Classification#
Co-authors
Prerequisites
Outcomes
Understand what problems classification solves
Evaluate classification models using a variety of metrics
# Uncomment following line to install on colab
#! pip install fiona geopandas xgboost gensim folium pyLDAvis descartes
Introduction to Classification#
We now move from regression to the second main branch of machine learning: classification.
Recall that the regression problem mapped a set of feature variables to a continuous target.
Classification is similar to regression, but instead of predicting a continuous target, classification algorithms attempt to apply one (or more) of a discrete number of labels or classes to each observation.
Another perspective is that for regression, the targets are usually continuous-valued, while in classification, the targets are categorical.
Common examples of classification problems are
Labeling emails as spam or not spam
Person identification in a photo
Speech recognition
Whether or not a country is or will be in a recession
Classification can also be applied in settings where the target isn’t naturally categorical.
For example, suppose we want to predict whether the unemployment rate for a state will be low (\(<3\%\)), medium (\(\in [3\%, 5\%]\)), or high (\(>5\%\)) but don’t care about the actual number.
Most economic problems are posed in continuous terms, so it may take some creativity to determine the optimal way to categorize a target variable so classification algorithms can be applied.
As many problems can be posed either as classification or regression, many machine learning algorithms have variants that perform regression or classification tasks.
Throughout this lecture, we will revisit some of the algorithms from the regression lecture and discuss how they can be applied in classification settings.
As we have already seen relatives of these algorithms, this lecture will be lighter on exposition and then build up to an application.
import datetime
import numpy as np
import pandas as pd
import seaborn as sns
import pandas_datareader.data as web
from sklearn import (
linear_model, metrics, neural_network, pipeline, preprocessing, model_selection
)
import matplotlib.pyplot as plt
%matplotlib inline
Warmup Example: Logistic Regression#
We have actually already encountered a classification algorithm.
In the recidivism example, we attempted to predict whether or not an individual would commit another crime by using a combination of the assigned COMPAS score and the individual’s gender or race.
In that example, we used a logistic regression model, which is a close relative of the linear regression model from the regression section.
The logistic regression model for predicting the likelihood of recidivism using
the COMPAS score as the single feature is written
where \(L\) is the logistic function: \(L(x) = \frac{1}{1 + e^{-x}}\).
To get some intuition for this function, let’s plot it below.
x = np.linspace(-5, 5, 100)
y = 1/(1+np.exp(-x))
plt.plot(x, y)
[<matplotlib.lines.Line2D at 0x7f520b73e720>]
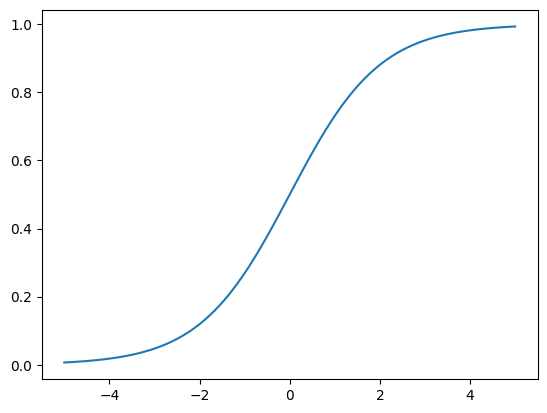
Notice that for all values of \(x\), the value of the logistic function is always between 0 and 1.
This is perfect for binary classification problems that need to output the probability of one of the two labels.
Let’s load up the recidivism data and fit the logistic regression model.
data_url = "https://raw.githubusercontent.com/propublica/compas-analysis"
data_url += "/master/compas-scores-two-years.csv"
df = pd.read_csv(data_url)
df.head()
X = df[["decile_score"]]
y = df["two_year_recid"]
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.25)
logistic_model = linear_model.LogisticRegression(solver="lbfgs")
logistic_model.fit(X_train, y_train)
beta_0 = logistic_model.intercept_[0]
beta_1 = logistic_model.coef_[0][0]
print(f"Fit model: p(recid) = L({beta_0:.4f} + {beta_1:.4f} decile_score)")
Fit model: p(recid) = L(-1.4442 + 0.2694 decile_score)
From these coefficients, we see that an increase in the decile_score leads
to an increase in the predicted probability of recidivism.
Suppose we choose to classify any model output greater than 0.5 as “at risk of recidivism”.
Then, the positive coefficient on decile_score means that there is some cutoff score above which all individuals will be labeled as high-risk.
Exercise
See exercise 1 in the exercise list.
Visualization: Decision Boundaries#
With just one feature that has a positive coefficient, the model’s predictions will always have this cutoff structure.
Let’s add a second feature the model: the age of the individual.
X = df[["decile_score", "age"]]
X_train, X_test, y_train, y_test = model_selection.train_test_split(
X, y, test_size=0.25, random_state=42
)
logistic_age_model = linear_model.LogisticRegression(solver="lbfgs")
logistic_age_model.fit(X_train, y_train)
beta_0 = logistic_age_model.intercept_[0]
beta_1, beta_2 = logistic_age_model.coef_[0]
print(f"Fit model: p(recid) = L({beta_0:.4f} + {beta_1:.4f} decile_score + {beta_2:.4f} age)")
Fit model: p(recid) = L(-0.8505 + 0.2470 decile_score + -0.0130 age)
Here, we see that an increase in the decile_score still leads to an increase in
the predicted probability of recidivism, while older individuals are slightly
less likely to commit crime again.
We’ll build on an example from the scikit-learn documentation to visualize the predictions of this model.
def plot_contours(ax, mod, xx, yy, **params):
"""
Plot the decision boundaries for a classifier with 2 features x and y.
Parameters
----------
ax: matplotlib axes object
mod: a classifier
xx: meshgrid ndarray
yy: meshgrid ndarray
params: dictionary of params to pass to contourf, optional
"""
Z = mod.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
out = ax.contourf(xx, yy, Z, **params)
return out
def fit_and_plot_decision_boundary(mod, X, y, **params):
# fit model
mod.fit(X, y)
# generate grids of first two columns of X
def gen_grid(xseries):
if xseries.nunique() < 50:
return sorted(xseries.unique())
else:
return np.linspace(xseries.min(), xseries.max(), 50)
x1, x2 = np.meshgrid(gen_grid(X.iloc[:, 0]), gen_grid(X.iloc[:, 1]))
# plot contours and scatter
fig, ax = plt.subplots()
plot_contours(ax, mod, x1, x2, **params)
x1_name, x2_name = list(X)[:2]
X.plot.scatter(x=x1_name, y=x2_name, color=y, ax=ax)
ax.set_xlabel(x1_name)
ax.set_ylabel(x2_name)
return ax
fit_and_plot_decision_boundary(
linear_model.LogisticRegression(solver="lbfgs"),
X_train, y_train, cmap=plt.cm.Greys
)
/home/runner/miniconda3/envs/lecture-datascience/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LogisticRegression was fitted with feature names
warnings.warn(
<Axes: xlabel='decile_score', ylabel='age'>
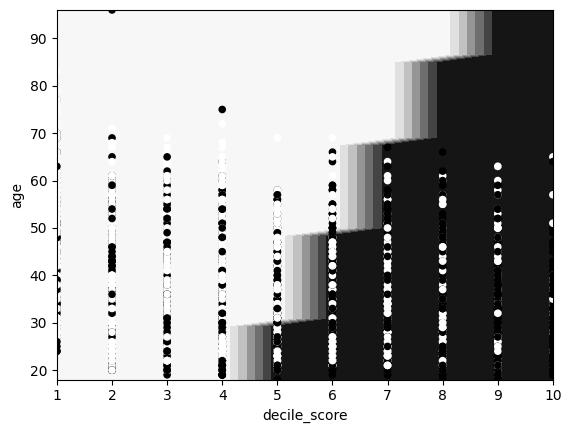
In this plot, we can clearly see the relationships we identified from the coefficients.
However, we do see that the model is not perfect, as some solid circles are in the light section and some light circles in the solid section.
This is likely caused by two things:
The model inside the logistic function is a linear regression – thus only a linear combination of the input features can be used for prediction.
Drawing a straight line (linear) that perfectly separates true observations from the false is impossible.
Exercise
See exercise 2 in the exercise list.
Model Evaluation#
Before we get too far into additional classification algorithms, let’s take a step back and think about how to evaluate the performance of a classification model.
Accuracy#
Perhaps the most intuitive classification metric is accuracy, which is the fraction of correct predictions.
For a scikit-learn classifier, this can be computed using the score method.
train_acc = logistic_age_model.score(X_train, y_train)
test_acc = logistic_age_model.score(X_test, y_test)
train_acc, test_acc
(0.6534195933456562, 0.667960088691796)
When the testing accuracy is similar to or higher than the training accuracy (as it is here), the model might be underfitting. Thus, we should consider either using a more powerful model or adding additional features.
In many contexts, this would be an appropriate way to evaluate a model, but in others, this is insufficient.
For example, suppose we want to use a classification model to predict the likelihood of someone having a rare, but serious health condition.
If the condition is very rare (say it appears in 0.01% of the population), then a model that always predicts false would have 99.99% accuracy, but the false negatives could have large consequences.
Precision and Recall#
In order to capture situations like that, data scientists often use two other very common metrics:
Precision: The number of true positives over the number of positive predictions. Precision tells us how often the model was correct when it predicted true.
Recall: The number of true positives over the number of actual positives. Recall answers the question, “What fraction of the positives did we get correct?”
In the rare health condition example, you may prefer a model with high recall (never misses an at-risk patient), even if the precision is a bit low (sometimes you have false positives).
On the other hand, if your algorithm filters spam emails out of an inbox, you may prefer a model with high precision so that when an email is classified as spam, it is very likely to actually be spam (i.e. non-spam messages don’t get sent to spam folder).
In many settings, both precision and recall are equally important and a compound metric known as the F1-score is used:
The F1 score is bounded between 0 and 1. It will only achieve a value of 1 if both precision and recall are exactly 1.
We can have scikit-learn produce a textual report with precision and recall.
Scikit-learn
report = metrics.classification_report(
y_train, logistic_age_model.predict(X_train),
target_names=["no recid", "recid"]
)
print(report)
precision recall f1-score support
no recid 0.67 0.73 0.69 2940
recid 0.64 0.57 0.60 2470
accuracy 0.65 5410
macro avg 0.65 0.65 0.65 5410
weighted avg 0.65 0.65 0.65 5410
ROC and AUC#
For classification algorithms, there is a tradeoff between precision and recall.
Let’s illustrate this point in the context of the logistic regression model.
The output of a logistic regression is a probability of an event or label.
To obtain a definite prediction from the algorithm, the modeler would first select a threshold parameter \(p\) such that all model outputs above the threshold are given the label of true.
As this \(p\) increases, the model must be relatively more confident before assigning a label of true.
In this case, the model’s precision will increase (very confident when applying true label), but the recall will suffer (will apply false to some true cases that had a model output just below the raised threshold).
Machine learning practitioners have adapted a way to help us visualize this tradeoff.
The visualization technique is known as the receiver operating characteristic – or more commonly used ROC – curve 1.
To understand this curve, consider two extremes choices for \(p\):
When \(p=1\), we will (almost surely) never predict any observation to have a label 1. In this case, the false positive rate will be equal to 0, as will the true positive rate.
When \(p=0\), we will predict that all observations always have a label of 1. The false positive rate and true positive rates will be equal to 1.
The ROC curve traces the relationship between the false positive rate (on the x axis) and the true positive rate (on the y axis) as the probability threshold \(p\) is changed.
Below, we define a function that uses scikit-learn to compute the true positive rate and false positive rates. Then we plot these rates against each other.
def plot_roc(mod, X, y):
# predicted_probs is an N x 2 array, where N is number of observations
# and 2 is number of classes
predicted_probs = mod.predict_proba(X)
# keep the second column, for label=1
predicted_prob1 = predicted_probs[:, 1]
fpr, tpr, _ = metrics.roc_curve(y, predicted_prob1)
# Plot ROC curve
fig, ax = plt.subplots()
ax.plot([0, 1], [0, 1], "k--")
ax.plot(fpr, tpr)
ax.set_xlabel("False Positive Rate")
ax.set_ylabel("True Positive Rate")
ax.set_title("ROC Curve")
plot_roc(logistic_age_model, X_test, y_test)
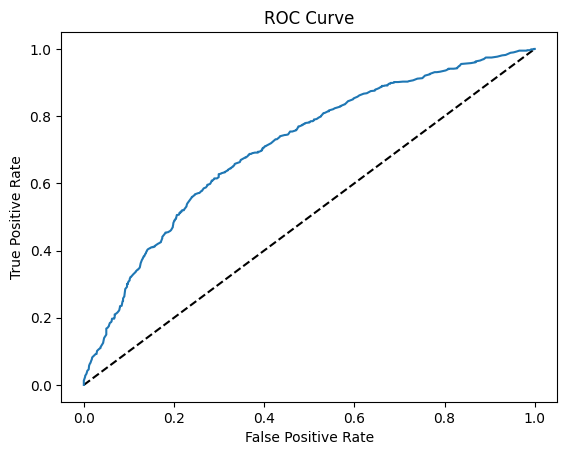
We can use the ROC curve to determine the optimal threshold value.
Since the output of our recidivism application model could potentially inform judicial decisions that impact the lives of individuals, we should be careful when considering a threshold value with low false positive rate vs high recall (low false negative rate).
We may choose to err on the side of low false negative rate so that when the model predicts recidivism, recidivism will likely occur – in other words, we would favor a high true positive rate even if the false positive rate is higher.
Exercise
See exercise 3 in the exercise list.
The ROC curve can also be used to do hyper-parameter selection for the model’s parameters.
To see how, consider a model with an ROC curve that has a single point at (0, 1) – meaning the true positive rate is 1 and false positive rate is zero or that the model has 100% accuracy.
Notice that integrating to obtain the area under the ROC curve returns a value of 1 for the perfect model.
The area under any other ROC curve would be less than 1.
Thus, we could use the area under the curve (abbreviated AUC) as an objective metric in cross-validation.
Let’s see an example.
predicted_prob1 = logistic_age_model.predict_proba(X)[:, 1]
auc = metrics.roc_auc_score(y, predicted_prob1)
print(f"Initial AUC value is {auc:.4f}")
# help(linear_model.LogisticRegression)
Initial AUC value is 0.7057
Exercise
See exercise 4 in the exercise list.
Neural Network Classifiers#
The final classifier we will visit today is a neural-network classifier, using the multi-layer perceptron network architecture.
Recall from the regression chapter that a multi-layer perceptron is comprised of a series of nested linear regressions separated by non-linear activation functions.
The number of neurons (size of weight matrices and bias vectors) in each layer were hyperparameters that could be chosen by modeler, but for regression, the last layer had to have exactly one neuron which represented the single regression target.
To use the MLP for classification tasks, we need to make three adjustments:
Construct a final layer with \(N\) neurons instead of 1, where \(N\) is the number of classes in the classification task.
Apply a softmax function on the network output.
Use the cross-entropy loss function instead of the MSE to optimize network weights and biases.
The softmax function applied to a vector \(x \in \mathbb{R}^N\) is computed as
In words, the softmax function is computed by exponentiating all the values, then dividing by the sum of exponentiated values.
The output of the softmax function is a probability distribution (all non-negative and sum to 1) weighted by the relative value of the input values.
Finally, the cross entropy loss function for \(M\) observations \(y\), with associated softmax vectors \(z\) is
where \(1_{y_j = i}\) is an indicator variable with the value of 1 if the observed class was equal to \(i\) for the \(j\) th observation, 0 otherwise.
All the same tradeoffs we saw when we used the multi-layer perceptron for regression will apply for classification tasks.
This includes positives like automated-feature enginnering and theoretically unlimited flexibility.
It also includes potential negatives, such as a risk of overfitting, high computational expenses compared to many classification algorithms, and lack of interpretability.
For a more detailed discussion, review the regression lecture.
Exercise
See exercise 5 in the exercise list.
Aside: Neural Network Toolboxes#
Thus far, we have been using the routines in scikit-learn’s neural_network package.
These are great for learning and exploratory analysis, as we have been doing, but are rarely used in production or real-world settings.
Why? 1) The scikit-learn routines do not leverage modern hardware like GPUs, so performance is likely much slower than it could be. 2) The routines only provide implementations of the most basic deep neural networks.
If you were to use neural networks in mission-critical situations, you would want to use modern neural network libraries such as Google’s tensorflow, Facebook’s pytorch, the Amazon-supported MXNet, or fastai.
Each of these toolkits has its own relative strengths and weaknesses, but we’ve seen tensorflow and pytorch used the most.
Thankfully, they all support Python as either the only or the primary point of access, so you will be well-prepared to start using them.
Application: Predicting US Recessions#
Let’s apply our new classification algorithm knowledge and use leading indicators to predict recessions in the US economy.
A leading indicator is a variable that moves or changes before the rest of the economy.
Many different leading indicators have been proposed – we’ll use a few of them.
We won’t explicitly prove that these variables are actually leading indicators, but will show a plot of each variables that lets us visually inspect the hypothesis.
Data Prep#
Let’s first gather the data from FRED.
start = "1974-01-01"
end = datetime.date.today()
def pct_change_on_last_year(df):
"compute pct_change on previous year, assuming quarterly"
return (df - df.shift(4))/df.shift(4)
def get_indicators_from_fred(start=start, end=end):
"""
Fetch quarterly data on 6 leading indicators from time period start:end
"""
# yield curve, unemployment, change in inventory, new private housing permits
yc_unemp_inv_permit = (
web.DataReader(["T10Y2Y", "UNRATE", "CBIC1", "PERMIT"], "fred", start, end)
.resample("QS")
.mean()
)
# percent change in housing prices and retail sales
hpi_retail = (
web.DataReader(["USSTHPI", "SLRTTO01USQ661S"], "fred", start, end)
.resample("QS") # already quarterly, adjusting so index is same
.mean()
.pipe(pct_change_on_last_year)
.dropna()
)
indicators = (
yc_unemp_inv_permit
.join(hpi_retail)
.dropna()
.rename(columns=dict(
USSTHPI="pct_change_hpi",
T10Y2Y="yield_curve",
UNRATE="unemp",
CBIC1="inventory",
SLRTTO01USQ661S="retail_sales",
PERMIT="house_permits"
))
)
return indicators
indicators = get_indicators_from_fred()
indicators.head()
| yield_curve | unemp | inventory | house_permits | pct_change_hpi | retail_sales | |
|---|---|---|---|---|---|---|
| DATE | ||||||
| 1976-04-01 | 0.801364 | 7.566667 | 58.961 | 1171.333333 | 0.074762 | 0.056936 |
| 1976-07-01 | 1.099687 | 7.733333 | 53.269 | 1345.000000 | 0.086339 | 0.037207 |
| 1976-10-01 | 1.467377 | 7.766667 | 19.461 | 1489.000000 | 0.080656 | 0.047523 |
| 1977-01-01 | 1.332222 | 7.500000 | 33.147 | 1562.000000 | 0.107535 | 0.037939 |
| 1977-04-01 | 1.248254 | 7.133333 | 49.461 | 1693.333333 | 0.111909 | 0.032931 |
Now, we also need data on recessions.
def get_recession_data():
recession = (
web.DataReader(["USRECQ"], "fred", start, end)
.rename(columns=dict(USRECQ="recession"))
["recession"]
)
# extract start and end date for each recession
start_dates = recession.loc[recession.diff() > 0].index.tolist()
if recession.iloc[0] > 0:
start_dates = [recession.index[0]] + start_dates
end_dates = recession.loc[recession.diff() < 0].index.tolist()
if (len(start_dates) != len(end_dates)) and (len(start_dates) != len(end_dates) + 1):
raise ValueError("Need to have same number of start/end dates!")
return recession, start_dates, end_dates
recession, start_dates, end_dates = get_recession_data()
Now, let’s take a look at the data we have.
def add_recession_bands(ax):
for s, e in zip(start_dates, end_dates):
ax.axvspan(s, e, color="grey", alpha=0.2)
axs = indicators.plot(subplots=True, figsize=(8, 6), layout=(3, 2), legend=False)
for i, ax in enumerate(axs.flatten()):
add_recession_bands(ax)
ax.set_title(list(indicators)[i])
fig = axs[0, 0].get_figure()
fig.tight_layout();
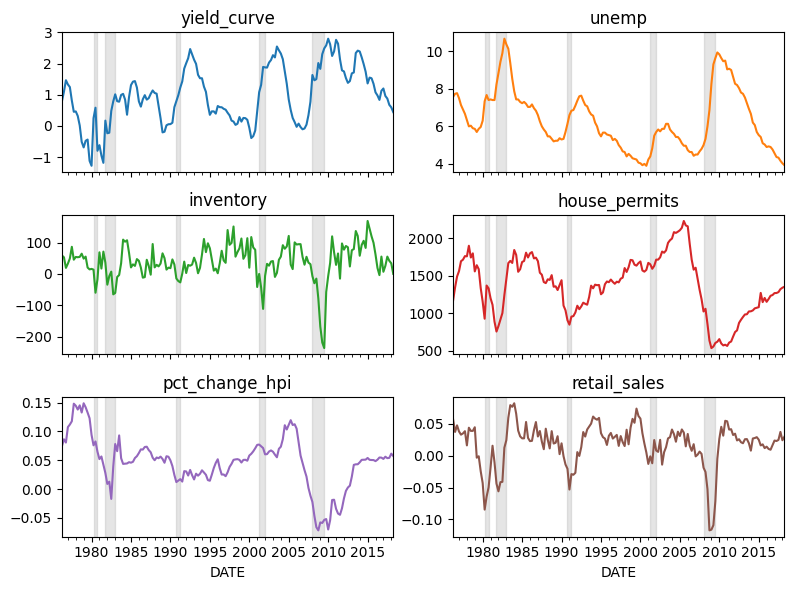
For each of the chosen variables, you can see that the leading indicator has a distinct move in periods leading up to a recession (noted by the grey bands in background).
Exercise
See exercise 6 in the exercise list.
How Many leads?#
If the variables we have chosen truly are leading indicators, we should be able to use leading values of the variables to predict current or future recessions.
A natural question is: how many leads should we include?
Let’s explore that question by looking at many different sets of leads.
def make_train_data(indicators, rec, nlead=4):
return indicators.join(rec.shift(nlead)).dropna()
def fit_for_nlead(ind, rec, nlead, mod):
df = make_train_data(ind, rec, nlead)
X = df.drop(["recession"], axis=1).copy()
y = df["recession"].copy()
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y)
mod.fit(X_train, y_train)
cmat = metrics.confusion_matrix(y_test, mod.predict(X_test))
return cmat
mod = pipeline.make_pipeline(
preprocessing.StandardScaler(),
linear_model.LogisticRegression(solver="lbfgs")
)
cmats = dict()
for nlead in range(1, 11):
cmats[nlead] = np.zeros((2, 2))
print(f"starting for {nlead} leads")
for rep in range(200):
cmats[nlead] += fit_for_nlead(indicators, recession, nlead, mod)
cmats[nlead] = cmats[nlead] / 200
for k, v in cmats.items():
print(f"\n\nThe average confusion matrix for {k} lag(s) was:\n {v}")
starting for 1 leads
starting for 2 leads
/home/runner/miniconda3/envs/lecture-datascience/lib/python3.12/site-packages/sklearn/metrics/_classification.py:407: UserWarning: A single label was found in 'y_true' and 'y_pred'. For the confusion matrix to have the correct shape, use the 'labels' parameter to pass all known labels.
warnings.warn(
starting for 3 leads
/home/runner/miniconda3/envs/lecture-datascience/lib/python3.12/site-packages/sklearn/metrics/_classification.py:407: UserWarning: A single label was found in 'y_true' and 'y_pred'. For the confusion matrix to have the correct shape, use the 'labels' parameter to pass all known labels.
warnings.warn(
starting for 4 leads
starting for 5 leads
starting for 6 leads
starting for 7 leads
starting for 8 leads
starting for 9 leads
starting for 10 leads
The average confusion matrix for 1 lag(s) was:
[[37.725 0.69 ]
[ 1.42 3.165]]
The average confusion matrix for 2 lag(s) was:
[[37.7 0.95 ]
[ 2.51 2.485]]
The average confusion matrix for 3 lag(s) was:
[[37.795 0.81 ]
[ 2.775 2.265]]
The average confusion matrix for 4 lag(s) was:
[[37.96 0.43]
[ 2.67 1.94]]
The average confusion matrix for 5 lag(s) was:
[[37.54 0.695]
[ 3.355 1.41 ]]
The average confusion matrix for 6 lag(s) was:
[[36.525 1.235]
[ 3.96 1.28 ]]
The average confusion matrix for 7 lag(s) was:
[[36.24 1.435]
[ 3.69 1.635]]
The average confusion matrix for 8 lag(s) was:
[[36.15 1.41 ]
[ 3.485 1.955]]
The average confusion matrix for 9 lag(s) was:
[[35.545 1.515]
[ 4.435 1.505]]
The average confusion matrix for 10 lag(s) was:
[[34.535 1.69 ]
[ 4.79 0.985]]
From the averaged confusion matrices reported above, we see that the model with only one leading period was the most accurate.
After that was the model with 4 leading quarters.
Depending on the application, we might favor a model with higher accuracy or one that gives us more time to prepare (the 4 quarter model).
Why did the 1-lead and 4-lead models perform better than models with another number of leads? Perhaps because different variables start moving a different number of periods before the recession hits.
The exercise below asks you to explore this idea.
Exercise
See exercise 7 in the exercise list.
Exercise
See exercise 8 in the exercise list.
Exercises#
Exercise 1#
Determine the level of this cutoff value. Recall that the COMPAS score takes on integer values between 1 and 10, inclusive.
What happens to the cutoff level of the decile_score when you change
the classification threshold from 0.5 to 0.7? What about 0.3? Remember this
idea – we’ll come back to it soon.
Exercise 2#
Experiment with different pairs of features to see which ones show the clearest decision boundaries.
Feed different X DataFrames into the fit_and_plot_decision_boundary function above.
Exercise 3#
Use the metrics.roc_curve function to determine an appropriate value
for the probability threshold, keeping in mind our preference for
high precision over high recall.
The third return value of metrics.roc_curve is an array of the
probability thresholds (p) used to compute each false positive rate and
true positive rate.
To do this problem, you may wish to do the following steps:
Concoct objective function in terms of the
fprandtpr.Evaluate the objective function using the
fprandtprvariables returned by themetrics.roc_curvefunction.Use
np.argminto find the index of the smallest value of the objective function.Extract the value at the margin index from the probability threshold values array.
Hint
If we cared about both precision and recall equally (we don’t here),
we might choose (fpr - tpr)**2 as one objective function. With this
objective function, we would find the probability threshold value
that makes the false positive and true positive rates as equal as
possible.
# your code here
Exercise 4#
The LogisticRegression class with default arguments implements the
regression including l2 regularization (it penalizes coefficient
vectors with an l2-norm).
The regularization strength is controlled by a parameter C that is
passed to the LogisticRegression constructor.
Smaller values of C lead to stronger regularization.
For example, LogisticRegression(C=10) would have weaker regularization
than LogisticRegression(C=0.5).
Your task here is to use the model_selection.cross_val_score method to select an
optimal level for the regularization parameter C. The scoring argument should be set
to roc_auc.
Refer to the example in the recidivism lecture for how
to use model_selection.cross_val_score.
# your code here
Exercise 5#
Use a multi-layer perceptron in our recidivism example via the neural_network.MLPClassifier class.
Experiment with different inputs such as:
The features to include
The number of layers and number of neurons in each layer
The l2 regularization parameter
alphaThe solver
See if you can create a model that outperforms logistic regression.
Keep in mind other things, like the degree of overfitting and time required to estimate the model parameters. How do these compare to logistic regression?
# your code here
Exercise 6#
Let’s pause here to take a few minutes and digest.
If the task is to use these leading indicators to predict a recession, would high recall or high precision be more important for our model?
Would your answer change if you worked at the Federal Reserve?
What if you worked at a news company such as the Economist or the New York Times?
Exercise 7#
Extend the logic from the previous example and allow a different number of leading periods for each variable.
How would you find the “optimal” number of leads for each variable? How could you try to avoid overfitting?
Use make_train_data_varying_leads function below to construct your model.
def make_train_data_varying_leads(indicators, rec, nlead):
"""
Apply per-indicator leads to each indicator and join with recession data
Parameters
----------
indicators: pd.DataFrame
A DataFrame with timestamps on index and leading indicators as columns
rec: pd.Series
A Series indicating if the US economy was in a recession each period
nlead: dict
A dictionary which maps a column name to a positive integer
specifying how many periods to shift each indicator. Any
indicator not given a key in this dictionary will not be
included in the output DataFrame.
Returns
-------
df: pd.DataFrame
A DataFrame with the leads applied and merged with the recession
indicator
Example
-------
```
df = make_train_data_varying_leads(
indicators,
recession,
nlead=dict(yield_curve=3, unemp=4)
)
df.shape[1] # == 3 (yield_curve, unemp, recession))
```
"""
cols = []
for col in list(indicators):
if col in nlead:
cols.append(indicators[col].shift(-nlead[col]))
X = pd.concat(cols, axis=1)
return X.join(rec).dropna()
# your code here!
Exercise 8#
Experiment with different classifiers. Which ones perform better or worse?
How accurate can you become for each accuracy metric (accuracy, precision, and recall)?
- 1
The name “receiver operating characteristic” comes from its origin; during World War II, engineers used ROC curves to measure how well a radar signal could be properly detected from noise (i.e. enemy aircraft vs. noise).